Summary
Generalizable policy learning in high-dimensional environments is facilitated by well-designed state representations, which can surface important features of an environment and hide irrelevant ones. These state representations are typically manually specified, or derived from other labor-intensive labeling procedures. We introduce two methods, LGA (Language-Guided Abstraction) and PLGA (Preference-Conditioned Language-Guided Abstraction), which use a combination of natural language supervision and background knowledge from language models (LMs) to autonomously build state representations tailored to unseen tasks. In LGA, a user first provides a (possibly incomplete) description of a target task in natural language; next, a pre-trained LM translates this task description into a state abstraction function that masks out irrelevant features; finally, an imitation policy is trained using a small number of demonstrations and LGA-generated abstract states. In PLGA, we observe that these abstractions also depend on a user’s preference for what matters in a task, which may be hard to describe or infeasible to exhaustively specify using language alone. Ergo, we propose using language models (LMs) to query for those preferences directly given knowledge that a change in behavior has occurred. In PLGA, we use the LM in two ways: first, given a text description of the task and knowledge of behavioral change between states, we query the LM for possible hidden preferences; second, given the most likely preference, we query the LM to construct the state abstraction.
LGA
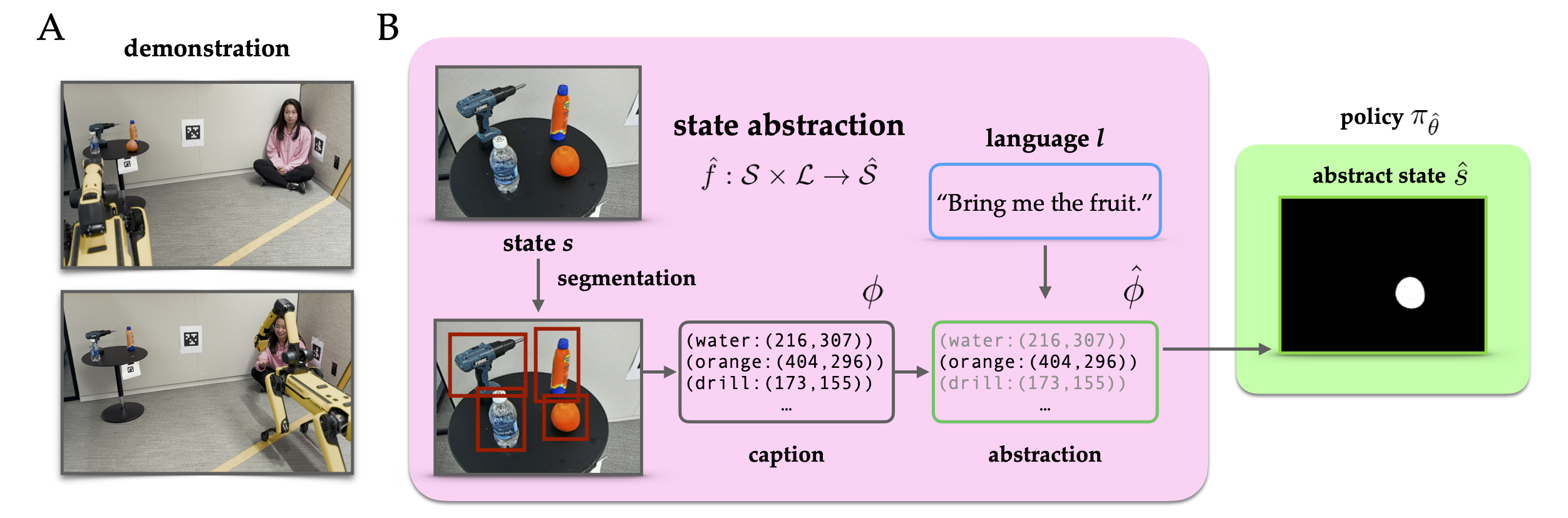
(A): Example demonstration in our environment, showing Spot picking up an orange and bringing it to the user. (B): LGA uses natural language supervision to create a state abstraction with task-relevant features identified by an LM. The policy is learned directly over this abstracted state.
PLGA
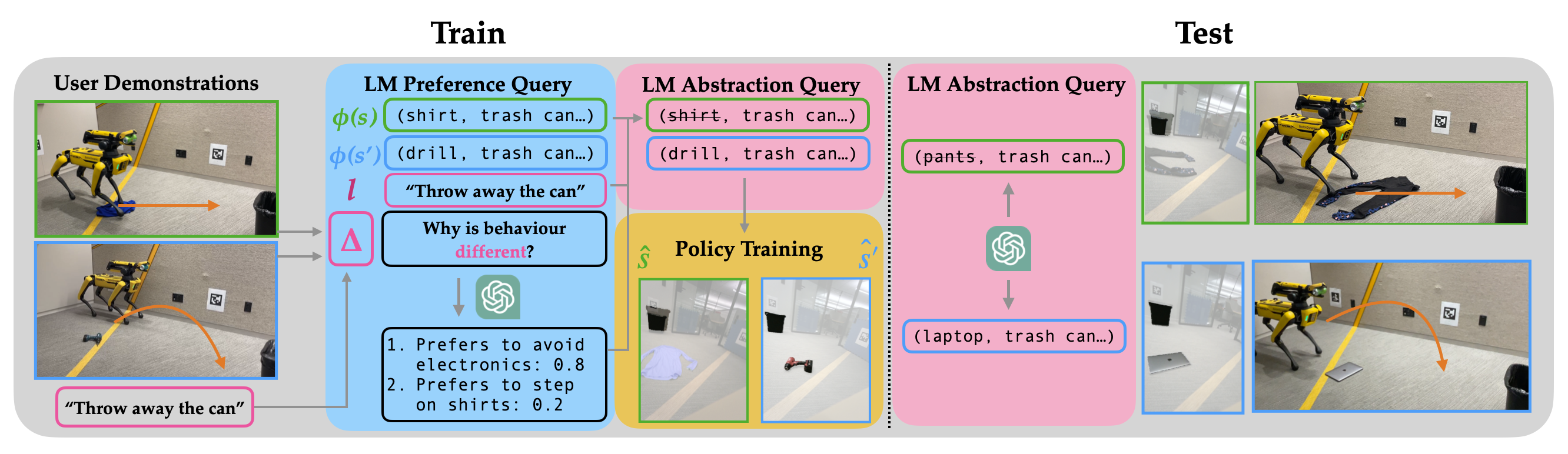
(Left): The robot uses a contrastive demonstration pair to identify a behavior change not captured by the language specification. Given this information, PLGA queries the LM for potential preferences that could explain this change. Finally, the robot uses its best preference estimate to query the LM for state abstractions and train a policy. (Right): At test time, PLGA generalizes to new states and language specifications using preference-conditioned abstractions.
LGA learns policies robust to visual distractors and linguistic ambiguities.
PLGA learns policies that respect implicit human preferences.
Team

Andi Peng
MIT

Belinda Z. Li
MIT

Ilia Sucholutsky
Princeton

Theodore R. Sumers
Princeton

Nishanth Kumar
MIT

Andreea Bobu
The AI Institute

Thomas L. Griffiths
Princeton

Jacob Andreas
MIT

Julie A. Shah
MIT
Acknowledgements
This template was originally made by Phillip Isola and Richard Zhang for a colorful ECCV project, and adapted to be mobile responsive by Jason Zhang. The code we built on can be found here.